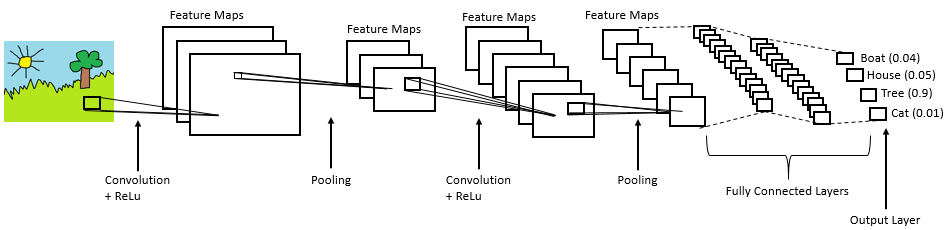
Trong neural networks, mạng Convolutional neural network (ConvNets or CNNs) là một trong những mạng chính để thực thi các bài toán nhận dạng, phân loại ảnh. Phát hiện đối tượng, nhận dạng khuôn mặt,… là một số lĩnh vực tiêu biểu mà CNNs sử dụng rộng rãi.
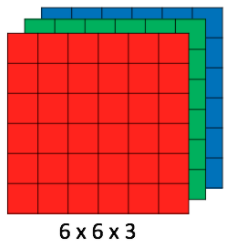
Phân loại hình ảnh trong CNNs bao gồm các bước lấy một hình ảnh làm đầu vào, xử lý và phân loại nó theo các danh mục nhất định cho trước (ví dụ: chó, mèo, lợn, gà …). Máy tính hiểu một ảnh là mảng các pixels và mảng đó phụ thuộc vào độ phân giải ảnh (resolution). Dựa vào độ phân giải ảnh, thì nó sẽ được xác định bởi ba tham số h x w x d (hlà chiều cao (height), w là chiều rộng (width), d là kích thước (dimension)). Ví dụ: Một ảnh 6 x 6 x 3 (3 đại diện các giá trị RGB (ảnh màu)), một ảnh kích thước 4 x 4 x 1 (1 đại diện cho ảnh grayscale(đen trắng)).
Về mặt kĩ thuật, các mô hình CNN (model) trong deep learning sẽ được train và test, mỗi ảnh đầu vào sẽ phải qua một lớp chập (convolution layers) bao gồm: các bộ lọc (Kernals), Pooling, fully connected layers (FC) và sử dụng một hàm activation function để phân loại một đối tượng có giá trị xác suất từ 0 đến 1. Hình dưới đây là một mô hình CNN hoàn chỉnh để xử lý hình ảnh đầu vào và phân loại đối tượng:
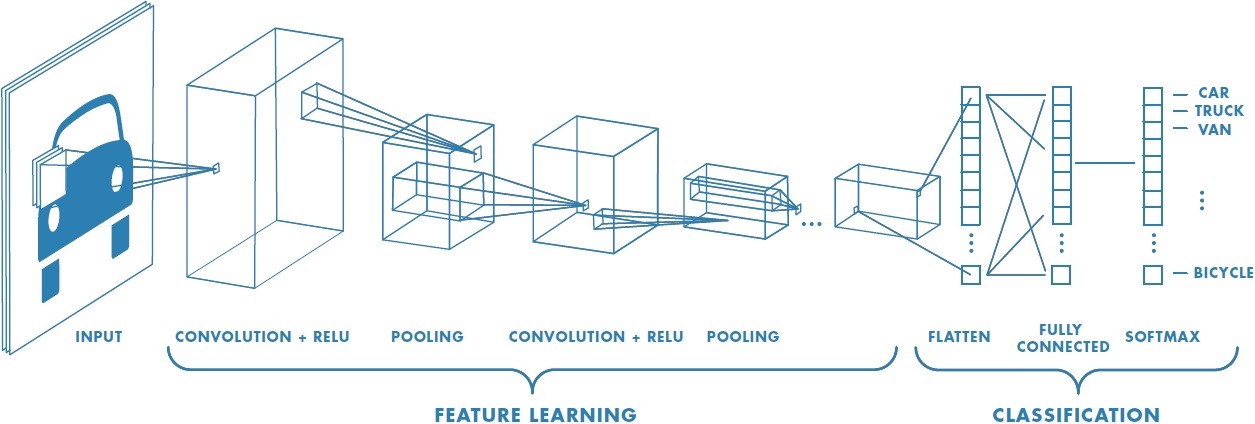
Ta bắt đầu đi tìm hiểu một số khái niệm cơ bản trong CNNs.
1. Convolution Layer
Convolution là layer đầu tiền dùng để trích xuất các tính năng từ một ảnh đầu vào. Về mặt toán học, đầu ra của layer này phụ thuộc vào hai đầu vào đó là: ma trận ảnh đầu vào và bộ lọc (kernel).
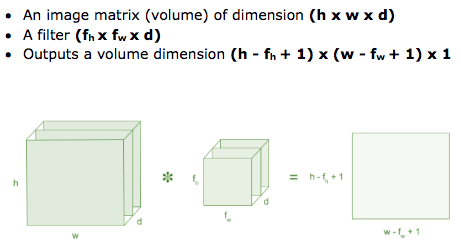
Giả sử rằng ta xét ma trận ảnh đầu vào có kích thức 5 x 5 và các giá trị pixel nhận giá trị 0,1 và bộ lọc ma trân 3 x 3 được mô tả như hình dưới:
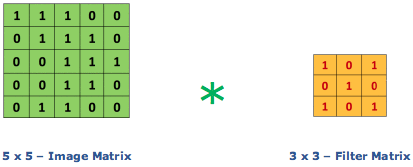
Khi đó, convolution (tích chập) của chúng được gọi là Feature Map là kết quả được mô tả như dưới đây:
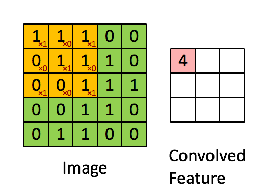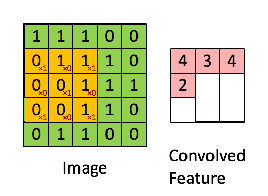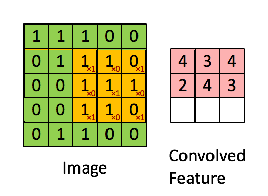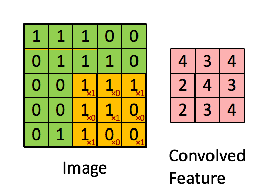
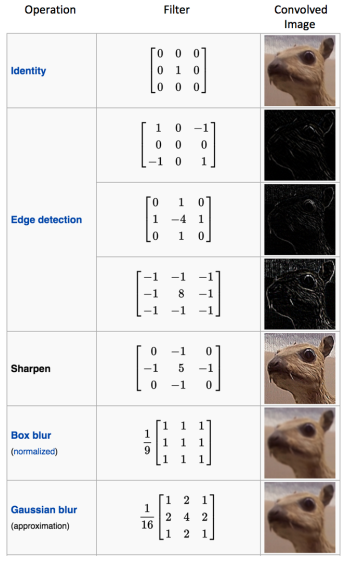
Convolution của một ảnh khi kết hợp với bộ lọc khác nhau có thể thực hiện các hoạt động khác nhau như phát hiện cạnh (edge detection), làm mờ (blur) và làm nét (sharpen). Ví dụ dưới cho thấy hình ảnh tích chập sau khi sử dụng các bộ lọc khác nhau:
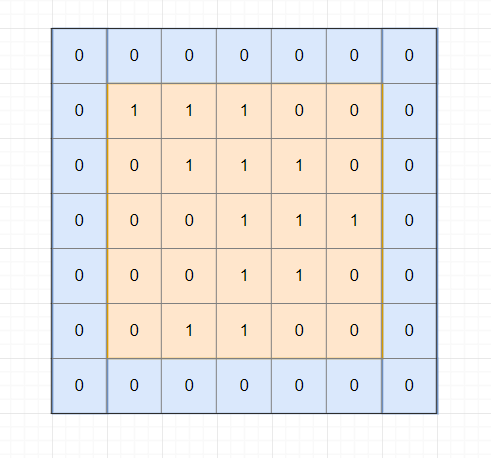
2. Padding
Nếu chỉ dùng tích convolution như trên thì kết quả đầu ra luôn có kích thước giảm đi. Kĩ thuật padding nhằm mục đích tăng kích thước ảnh sau bộ lọc bằng cách thêm viền cho ma trận bằng k hàng hoặc cột các phần tử 0 rồi thực hiện convolution. Ví dụ stride 1, padding 1 cho ma trận 5 x 5 sau:
Note: Nếu không nói gì đến strides thì mặc định nó có stride bằng 1 (tức là đi lần lượt qua tất cả các ô trong bảng).
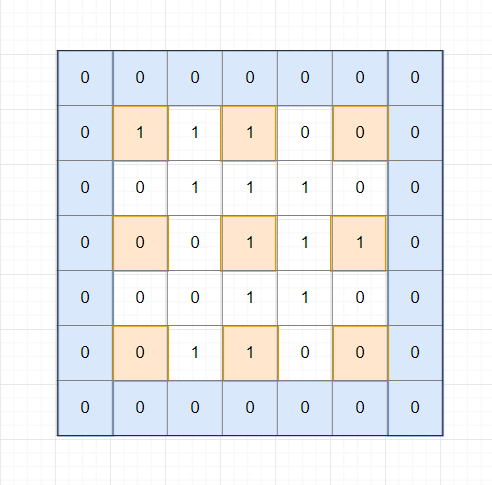
3. Strides
Kĩ thuật strides nhằm mục đích giảm kích thước ảnh bằng cách nhảy qua k bước nào đó rồi thực hiện convolution cho nó. Ví dụ stride 2, padding 1 cho ma trận 5 x 5 sau:
4. Non Linearity (ReLU)
ReLU là hàm phi tuyến tính (tên gọi: Rectified Linear Unit), và nó có giá trị bằng: f(x) = max(0,x). Hàm ReLU quan trọng là ví nó thể hiện được tính phi tuyến trong ConvNet và đồng thời, trong thế giới thực tế, thì chúng ta mong muốn chỉ học những giá trị tuyến tính không âm.
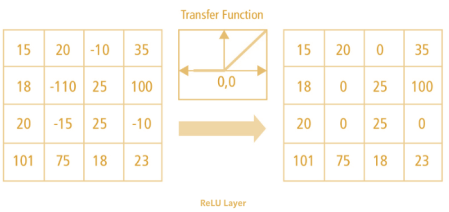
Có một số hàm như hàm tanh, sigmoid có thể thay thế hàm ReLU. Hầu hết, các nghiên cứu thường sử dụng hàm ReLU vì performance của nó tốt hơn hai loại kia.
5. Pooling Layer
Pooling layers làm giảm số lượng tham số khi hình ảnh quá lớn nhưng vẫn giữ được những đặc trưng của ảnh. Thông thường, spatial pooling layer có các loại sau:
- Max Pooling
- Average Pooling
- Sum Pooling
Max pooling lấy phần tử lớn nhất của feature map. Average pooling thì lấy phần tử trung bình của nhóm trong feature map, còn sum pooling thì lấy tổng tất cả các phần tử của feature map. Đây là một ví dụ:
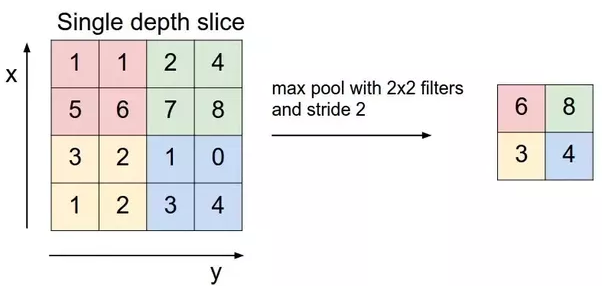
6. Fully Connected Layer
Layer được gọi là FC layer, mục đích là làm phẳng ma trận, đưa vector qua một lớp neural network đây đủ.
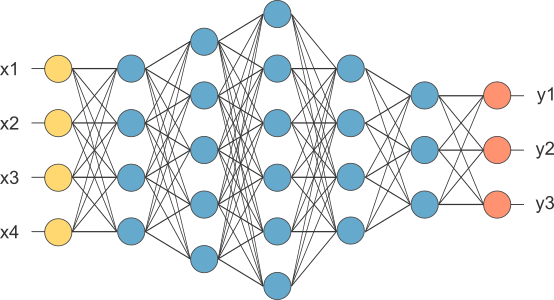
Trong sơ đồ trên, ma trận feature map được chuyển đổi thành các vector (x1,x2,x3,…). Sau FC layers, tạo ra một mô hình cuối (y1,y2,y3). Cuối cùng, sau activation function như softmax hoặc sigmoid để phân loại đầu ra như chó, mèo, lợn, gà,… Kiến trúc tổng thể như sau: